

In what is being described as a watershed moment for music technology in 2026, a growing number of music producers and artists are reporting the unsettling discovery of their own music appearing within the vast datasets used to train artificial intelligence models for music generation. This phenomenon, brought to wider public attention by investigative work from Alex Reisner at The Atlantic, reveals a situation potentially more pervasive and problematic than many creators currently realize. The implications extend beyond intellectual property concerns, touching upon the very definition of creativity, authorship, and the ethical responsibilities of Big Tech companies.
The Unveiling of Training Data: A Digital Scavenger Hunt
The recent surge in artist awareness can be directly attributed to The Atlantic‘s "AI Watchdog" series, spearheaded by Alex Reisner. The publication has made its research tools accessible, allowing artists to search public datasets for their own work without a paywall. A simple search query through Reisner’s investigative platform can reveal whether an artist’s name appears in various publicly available datasets that form the bedrock of many generative music products. These datasets, often amassed through extensive web scraping, are the raw material from which AI models learn to synthesize new audio.
One prominent example highlighted is the Berlin-based artist Hainbach, who discovered an astonishing 151 of his songs within a single dataset. This revelation, shared widely on social media, underscores the sheer volume of music being ingested by AI systems. The datasets themselves are often massive in scale. For instance, one collection mentioned, assembled by the German nonprofit LAION, reportedly contains over 12.3 million music tracks, totaling an estimated 91 years of audio. This particular dataset has received funding from entities like Hugging Face and Stability AI’s co-founder, Emad Mostaque, indicating its significance within the AI development ecosystem.
While these datasets often contain metadata or pointers to music rather than the full audio files, their public accessibility enables AI developers to link back to original sources. The lack of robust legal precedents and the often-unclear enforcement of usage policies create a fertile ground for automated scraping and data ingestion. This raises significant questions about the consent and compensation of artists whose work contributes to these powerful AI tools.
Beyond Public Datasets: The "Iceberg" of Data Ingestion
The findings from The Atlantic‘s research, while alarming, are presented as merely the "tip of the iceberg." Many generative AI music platforms are not transparent about the specific datasets they utilize for training. This lack of disclosure means that artists whose work does not appear in the publicly searchable databases may still be contributing to AI training sets through less transparent or undisclosed channels.
Google’s development of its AI music model, Lyria 3, serves as a case study for this broader issue. In its announcement, Google stated it was "using materials that YouTube and Google has a right to use under our terms of service, partner agreements, and applicable law." This statement has been interpreted by many as an indication that Lyria 3 was trained on music uploaded to YouTube, potentially including content delivered through Digital Service Providers (DSPs). This interpretation has led to legal challenges, with musicians suing Google. Google’s defense, including a motion to dismiss the lawsuit, has been particularly concerning. The company has neither confirmed nor denied the use of specific training data while simultaneously arguing that its Terms of Service grant them the right to use user-uploaded content for such purposes. This stance suggests a broad interpretation of user agreement that could encompass extensive data utilization for AI training.
While Google’s Magenta team has indicated that their Magenta RealTime 2 project utilized stock audio and MIDI files rather than artist-specific works, the broader implications of Google’s approach to data usage across its platforms remain a significant concern. The widespread acceptance of user agreements without full comprehension of their data usage clauses by millions of users creates a vast, often unacknowledged, repository of creative material available for AI training.
Companies like Suno have also publicly acknowledged using data under terms similar to Google’s. However, like Google, Suno has not detailed the specific composition of its training sets, often presenting generated content as entirely original. This approach fuels ongoing debates about the nature of AI-generated output and its relationship to the source material.
The potential for legal action is escalating. The ongoing class-action lawsuits filed by writers against OpenAI and Anthropic over the use of their copyrighted works in AI training data serve as a precedent. Similar legal challenges are now being considered by musicians whose work may have been used without explicit consent or compensation.
Deconstructing "Intelligence": Prediction vs. Creativity
The current discourse surrounding generative AI often employs anthropomorphic language, using terms like "training," "learning," and "intelligence." However, a more technical understanding reveals that these models are fundamentally predictive. As researchers delve deeper, the distinction between human creativity and the pattern-reproducing capabilities of AI becomes clearer.
Susan Rogers, a renowned audio scientist and producer with extensive experience in neuroscience and psychology, has spoken about the fundamental differences between human musical intelligence and AI’s predictive capabilities. She emphasizes that AI models, while sophisticated, operate by identifying and replicating patterns within their training data. This process, mathematically speaking, is akin to advanced auto-completion rather than genuine creative ideation. The concept of "tokens," where data is broken down into smaller units for processing, further illustrates this mechanistic approach.
This distinction is critical because it highlights the potential for AI-generated music to lack the depth, nuance, and emotional resonance that characterize human artistry. When AI models reproduce recognized patterns without the underlying human experience, the output can become derivative or, in the worst-case scenario, a bland amalgamation of existing sounds – a phenomenon sometimes referred to as "AI slop."
The Erosion of Originality and the Perils of "Pink Slime"
The implications of this data ingestion model are multifaceted and deeply concerning. Firstly, the lack of transparency and consent surrounding training data raises significant ethical and legal issues. Secondly, the process of tokenizing and reassembling human creative output risks devaluing authorship and originality.
If AI-generated music is too closely aligned with its source material, it can be perceived as plagiarism. Conversely, if it deviates significantly, it risks becoming meaningless, stripped of the cultural context and emotional weight that gave the original music its impact. This leads to a situation where AI output can be either a direct (and potentially infringing) copy or a hollow imitation.
The term "pink slime" has been used to describe the potentially bland and uninspired nature of AI-generated music that lacks the depth of human creation. An example cited is the use of a misconstrued version of New Radicals’ "You Get What You Give" for Czech figure skaters. While the lyrics were recognizable, the musical context that imbued them with meaning was distorted, resulting in a performance that, while technically functional, lacked the original song’s impact. This illustrates how AI can replicate surface-level elements while failing to grasp the underlying artistic intent.
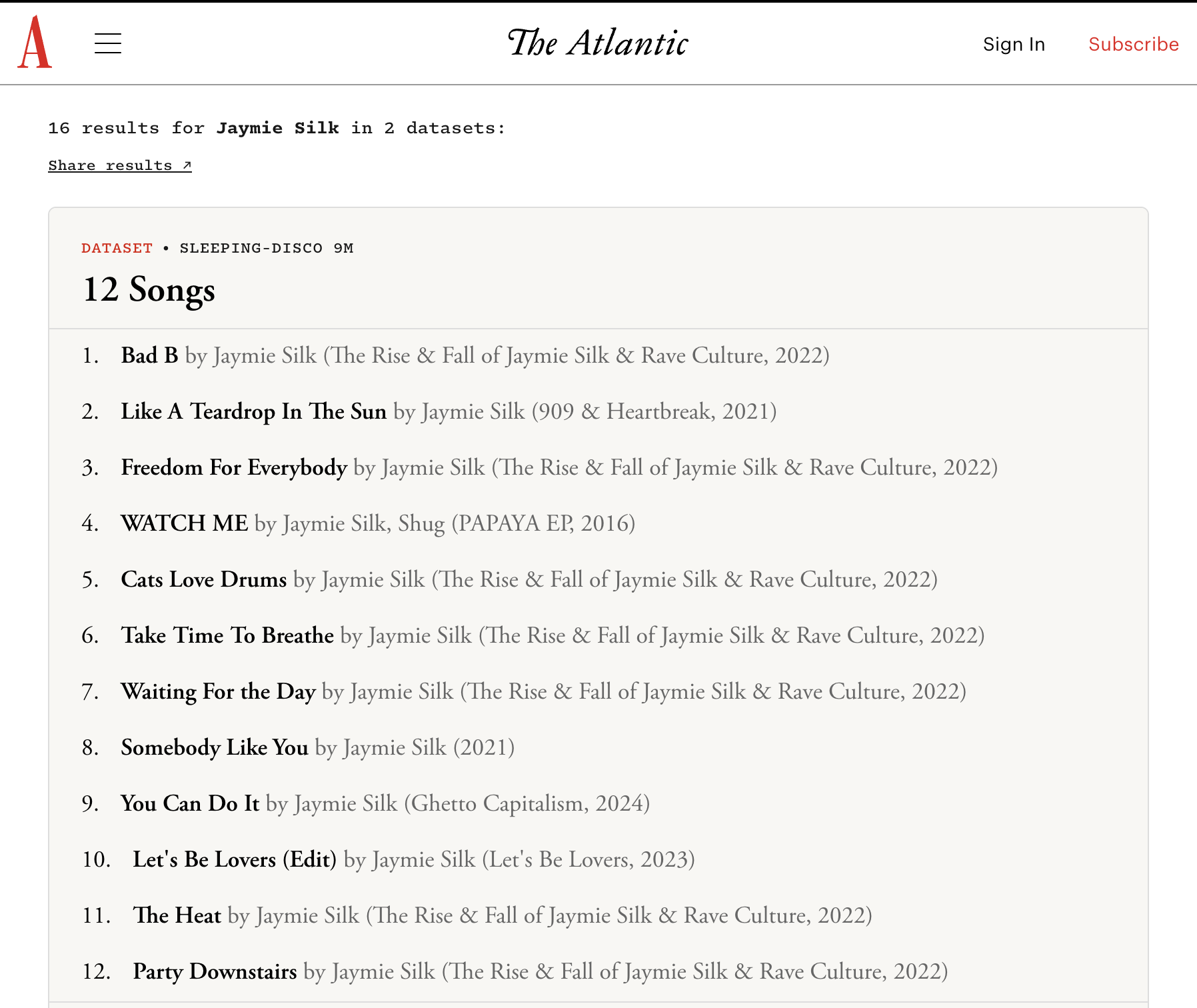
The situation is further complicated by the use of datasets like SLEEPING-DISCO 9M, which were built by scraping lyrics and associated metadata from platforms like Genius. While these datasets aim to enhance generative audio quality, their use in AI product development often violates the terms of their original licenses, which typically prohibit commercial and derivative uses. This constitutes a dual violation: abusing source material and breaching licensing agreements.
Systemic Inequities and the Digital Colonialism of Music
The issue of AI music generation is also deeply intertwined with systemic inequities, including classism and racism. Historically marginalized communities, particularly Black artists, have been disproportionately influential in shaping global music trends, from soul and hip-hop to Afrobeats. Their contributions, often born out of economic hardship and structural oppression, are now being leveraged by AI systems without commensurate recognition or compensation.
Artists like SZA have pointed out that while Black artists constitute a significant portion of the population and heavily influence global sound, they lack adequate legislative protection. SZA’s observation that she "ain’t heard a white AI song yet" highlights the perception that AI music generation, at least in its current iteration, is heavily reliant on and influenced by Black musical innovation. This raises concerns about digital colonialism, where the creative output of one group is appropriated and monetized by another, often without fair restitution.
Jaymie Silk, in a widely shared post, articulates this sentiment by stating, "The most rhythmically dense, emotionally legible, culturally loaded music in the world is Black music." He emphasizes that generations of innovation in genres like house, soul, hip-hop, and R&B were built under immense economic pressure and systemic theft. The current AI landscape, where these rich musical traditions are ingested and replicated by AI models, risks perpetuating this historical pattern of exploitation.
This dynamic is exacerbated by the financial precarity of many independent artists. While major record labels may negotiate deals with AI companies to protect and compensate their star artists, emerging and independent musicians, particularly those from the Global South or other marginalized regions, are likely to be left without recourse. This creates a further widening of the economic gap, benefiting Big Tech and financial investors at the expense of creators.
The Path Forward: Transparency and Critical Engagement
The current landscape of generative AI music presents a complex and ethically challenging scenario. The lack of transparency regarding training data, the potential for copyright infringement, and the perpetuation of systemic inequities demand critical examination. The widespread availability of tools to investigate training data, pioneered by initiatives like The Atlantic‘s "AI Watchdog," is a crucial step in empowering artists and fostering accountability.
Moving forward, a commitment to frank discussions and radical transparency is essential. This includes not only understanding how AI models are built but also critically assessing their implications beyond the hype. Objective analysis, rather than partisan advocacy, is needed to navigate the complex ethical and legal terrain.
The industry is at a critical juncture. The potential for AI to revolutionize music creation is undeniable, but this innovation must not come at the cost of artists’ rights, creative integrity, and the equitable distribution of value. The future of music hinges on addressing these challenges proactively, ensuring that technological advancement serves rather than exploits the human creativity it seeks to emulate. The ongoing dialogue and investigative journalism are vital in illuminating these complex issues and driving toward more responsible and ethical AI development in the music industry.








